Quantum Generative Adversarial Network¶
Copyright (c) 2021 Institute for Quantum Computing, Baidu Inc. All Rights Reserved.
Classical Generative Adversarial Network¶
Introduction to Generative Adversarial Network¶
Generative Adversarial Network (GAN) is a generative model, which is a breakthrough in deep learning in recent years [1]. It contains two parts: the generator $G$ and the discriminator $D$. The generator accepts a random noise signal and uses it as input to generate the data we expect. The discriminator evaluates the received data $x$ and outputs a probability $P(x)$ that the data $x$ is real.
Nash Equilibrium¶
Here we use the idea of Nash equilibrium to discuss the convergence problem of GAN.
Nash equilibrium refers to a non-cooperative game involving two or more participants, assuming that each participant knows other participants' equilibrium strategies. No participant can change one's strategy to benefit. In the game theory, if each participant chooses his strategy, and no player can benefit by changing the strategy while other participants remain the same, then the current set of strategy choices and their corresponding results constitute Nash Equilibrium.
We can regard the training process of GAN as a game process between generator and discriminator. No matter what the generator's strategy is, the best strategy of the discriminator is to try to distinguish the real data and the generated data. And regardless of the strategy of the discriminator, the best strategy for the generator is to make the discriminator unable to distinguish. This game is a zero-sum game, which is one of non-cooperative game. That is, one party gains while the other party must lose. Therefore, there exists the Nash equilibrium strategy in the game between the generator and the discriminator. When there are enough samples of real data and the learning ability of both parties is strong enough, a Nash equilibrium point will eventually be reached. The generator has the ability to generate real data, and the discriminator can no longer distinguish between generated data and real data.
GAN adopts the idea of Nash equilibrium. In GAN, the generator and the discriminator are playing a non-cooperative game. No matter what strategies the generator adopts, the best strategy of the discriminator is to discriminate as much as possible; and no matter what strategies the discriminator adopts, the best strategy of the generator is to make the discriminator unable to discriminate as much as possible. Therefore, the two parties' strategic combination in the game and the corresponding results constitute the Nash equilibrium. When the Nash equilibrium is reached, the generator can to generate real data, and the discriminator cannot distinguish between the generated data and the real data.
Optimization goal¶
In GAN, we want to get an excellent generator (but only an excellent discriminator can accurately determine whether the generator is excellent). Our training's ideal result is that the discriminator cannot identify whether the data comes from real data or generated data.
Therefore, our objective function is as follows:
$$ \min_{G}\max_{D} V(G,D)= \min_{G}\max_{D}\mathbb{E}_{x\sim P_{data}}[\log D(x)] +\mathbb{E}_{z\sim P_{z}}[\log(1-D(G(z)))]. \tag{1} $$Here, $G$ represents the parameters of the generator and $D$ represents the parameters of the discriminator. In the actual process, the alternate training method is usually adopted; that is, first fix $G$, train $D$, then fix $D$, train $G$, and repeat. When the two's performance is sufficient, the model will converge, and the two will reach the Nash equilibrium.
Advantages¶
- Compared with other generative models, GAN generates better results.
- Theoretically, as long as it is a differentiable function, it can be used to build generators and discriminators, so it can be combined with deep neural networks to make deep generative models.
- Compared with other generative models, GAN does not rely on prior assumptions, and we do not need to assume the probability distribution and law of the data in advance.
- The form of data generated by GAN is also very simple, just forward propagation through the generator.
Disadvantages¶
- GAN does not require pre-modeling. Too much freedom makes training difficult to converge and unstable.
- GAN has a vanishing gradient problem. In this case, there is no loss in the training of the discriminator, so there is no adequate gradient information to pass back to the generator to optimize itself.
- There may be a problem of model collapse in the learning process of GAN. The generator degenerates, always generating the same sample points, and cannot continue learning. The discriminator also points to similar sample points in similar directions, and the model parameters are no longer updated, but the actual effect is feeble.
Quantum Generative Adversarial Network¶
The quantum generative adversarial network is similar to the classical one, except that it is no longer used to generate classical data but generate quantum states [2-3]. In practice, if we have a quantum state, it will collapse to a certain eigenstate after observation and cannot be restored to the previous quantum state. Therefore, if we have a method that generates many identical (or similar) quantum states based on the existing target quantum state, it will be very convenient for our experiments.
Assuming that our existing target quantum states all come from a mixed state, they belong to the same ensemble, and their density operator is $\rho$. Then we need to have a generator $G$ whose input is noise data, denoted by the ensemble $\rho_{z}=\sum_{i}p_{i}|z_{i}\rangle\langle z_ {i}|$. Therefore, we take out a random noise sample $|z_{i}\rangle$ every time and get the generated quantum state $|x\rangle=G|z_{i}\rangle$ after passing through the generator. We expect the generated $| x\rangle$ that is close to the target quantum state $\rho$.
It is worth noting that for the ensemble of the target state and the ensemble of the noise data mentioned above, we think that there exists a physical device that can generate a quantum state from the ensemble. According to quantum physics, We can get a genuinely random quantum state every time. However, in computer programs, we need to simulate this process.
We expect the discriminator to judge whether the quantum state we input is an existing target state or a generated quantum state. This process needs to be given by measurement.
A simple example¶
Problem Description¶
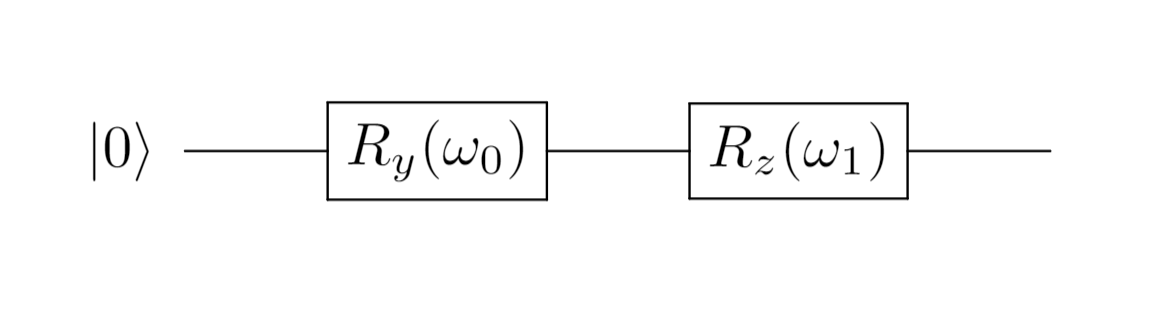
For simplicity, we assume that the existing target quantum state is a pure state, and the input state for the generator is $|0\rangle$.
The circuit to prepare the existing target quantum state:
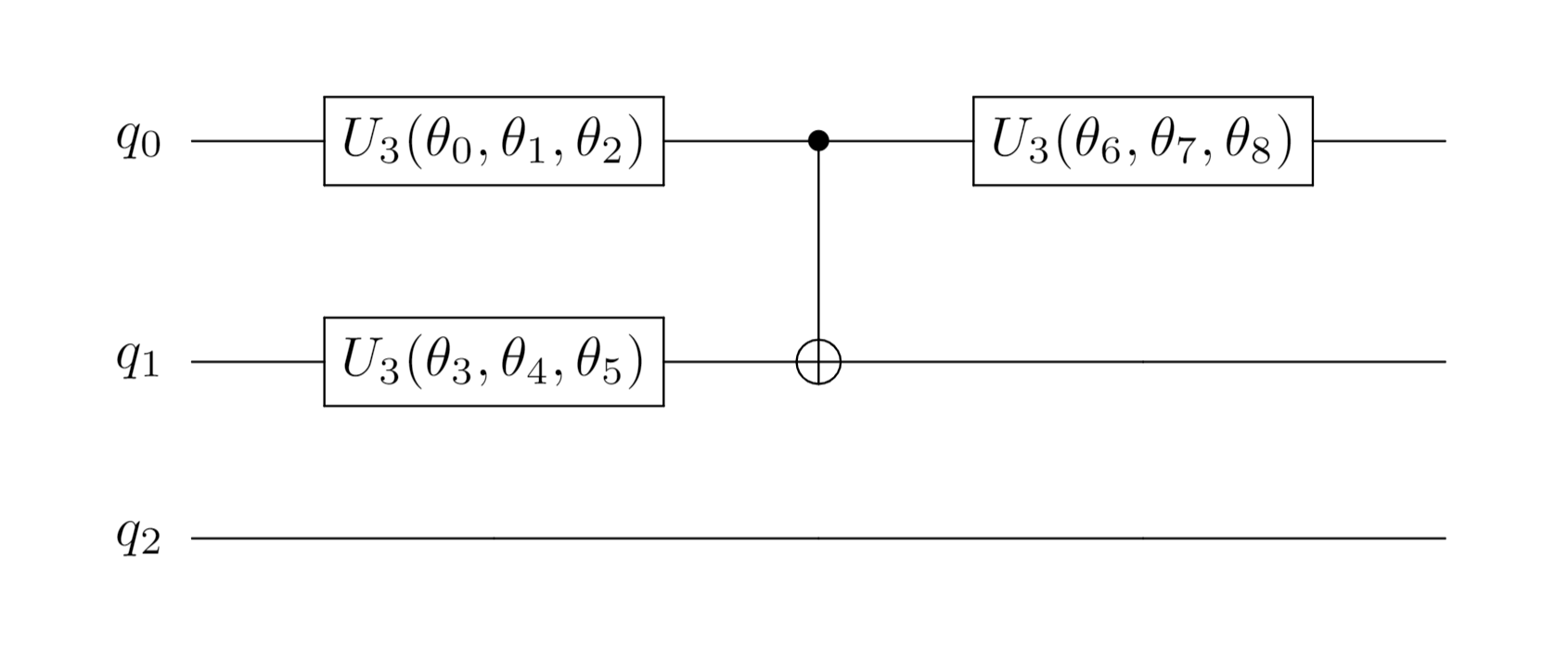
The circuit of the generator is:
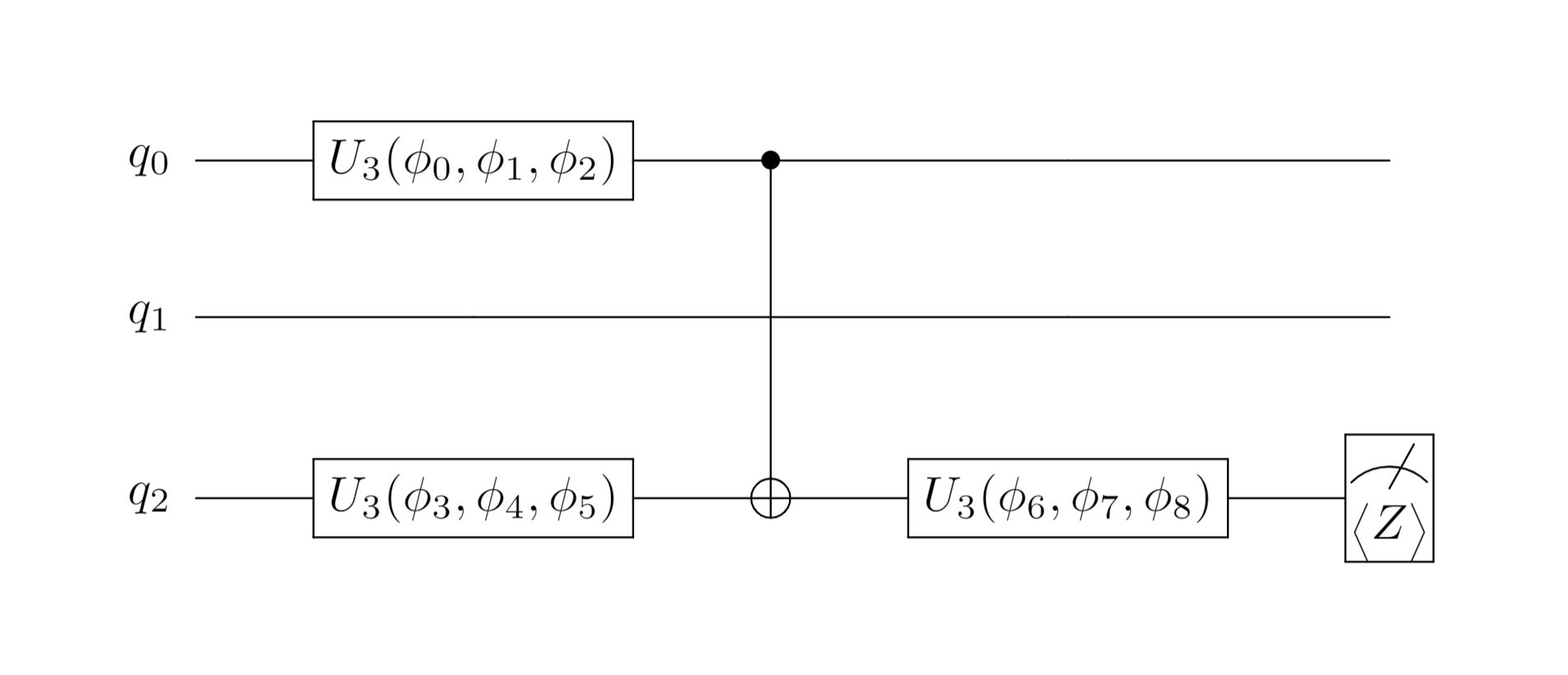
The circuit of the discriminator is:
By measuring the quantum state output by the discriminator, we can get the probability of judging the target state as the target state $P_{T}$ and the probability of judging the generated state as the target state $P_{G}$.
Specific process¶
Assuming that the existing target quantum state is $|\psi\rangle$, the quantum state generated by the generator is $|x\rangle=G|00\rangle$ (the generator uses a two-qubit circuit, of which the 0th qubit is a generated quantum state).
The discriminator discriminates the data and obtains the quantum state $|\phi\rangle$ when the input is the target state, $|\phi\rangle=D(|\psi\rangle\otimes |00\rangle)$; When the input is generated state, $|\phi\rangle=D(G\otimes I)|000\rangle$.
For the quantum state obtained by the discriminator, we also need to use the Pauli Z gate to measure the third qubit so as to obtain the judgment result of the input quantum state by the discriminator (that is, the probability that the discriminator thinks the input is the target state). First there is $M_{z}=I\otimes I\otimes\sigma_{z}$, and the measurement result is $\text{disc}_\text{output}=\langle\phi|M_{z}|\phi\rangle$, so the probability of the measurement that the result is the target state is $P=(\text{disc}_\text{output}+1)/2$.
We define the loss function of the discriminator as $\mathcal{L}_{D}=P_{G}(\text{gen}_\theta, \text{disc}_\phi)-P_{T}(\text{disc}_\phi)$, The loss function of the generator is $\mathcal{L}_{G}=-P_{G}(\text{gen}_\theta, \text{disc}_\phi)$. Here, $P_{G}$ and $P_{T}$ are the expressions of $P=(\text{disc}_\text{output}+1)/2$, when the input quantum state is the generated state and the target state, respectively. gen_theta and disc_phi are the parameters of the generator and discriminator circuits.
So we only need to optimize the objective function $\min_{\text{disc}_\phi}\mathcal{L}_{D}$ and $\min_{\text{gen}_\theta}\mathcal{L}_{G}$ respectively. The discriminator and generator can be alternately trained.
Paddle Quantum Implementation¶
First import the relevant packages.
import numpy as np
import scipy
import warnings
import paddle
import paddle_quantum
from paddle_quantum.state import zero_state
from paddle_quantum.ansatz import Circuit
from paddle_quantum import Hamiltonian
from paddle_quantum.gate import *
from paddle_quantum.loss import ExpecVal
from paddle_quantum.qinfo import partial_trace
from tqdm import tqdm
warnings.filterwarnings("ignore")
Then define our network model QGAN.
# set the backend to density_matrix
paddle_quantum.set_backend('density_matrix')
class QGAN():
def __init__(self, target_state, LR, ITR, ITR_D, ITR_G):
"""
parameters
target_state: target state
LR: learning rate
ITR: number of iterations
ITR_D: number of iterations for discriminator
ITR_G: number of iterations for generator
"""
self.target_state = target_state.clone()
# Quantum circuit of generator
self.generator = Circuit(3)
self.generator.u3([0, 1])
self.generator.cnot([0, 1])
self.generator.u3(0)
# Quantum circuit of the discriminator
self.discriminator = Circuit(3)
self.discriminator.u3([0, 2])
self.discriminator.cnot([0, 2])
self.discriminator.u3(0)
# Hyperparameters of training
self.LR = LR
self.ITR = ITR
self.ITR_D = ITR_D
self.ITR_G = ITR_G
# Optimizer
self.optimizer = paddle.optimizer.SGD(
learning_rate=self.LR,
parameters=self.generator.parameters() + self.discriminator.parameters(),
)
def disc_target_as_target(self):
"""
The probability that the discriminator judges the target state as the target state
"""
state = self.discriminator(self.target_state)
expec_val_func = ExpecVal(Hamiltonian([[1.0, 'z2']]))
# The judgment result of the discriminator on the target state
target_disc_output = expec_val_func(state)
prob_as_target = (target_disc_output + 1) / 2
return prob_as_target
def disc_gen_as_target(self):
"""
The probability that the discriminator judges the generated state as the target state
"""
# Get the quantum state generated by the generator
gen_state = self.generator()
state = self.discriminator(gen_state)
# The judgment result of the discriminator on the generated state
expec_val_func = ExpecVal(Hamiltonian([[1.0, 'z2']]))
gen_disc_output = expec_val_func(state)
prob_as_target = (gen_disc_output + 1) / 2
return prob_as_target
def gen_loss_func(self):
"""
Calculate the loss function of the generator, the interval of the loss value is [-1, 0],
0 means extremely poor generation effect, -1 means excellent generation effect
"""
return -1 * self.disc_gen_as_target()
def disc_loss_func(self):
"""
Calculate the loss function of the discriminator, the loss value range is [-1, 1],
-1 means perfect distinction, 0 means indistinguishable, 1 means inverted distinction
"""
return self.disc_gen_as_target() - self.disc_target_as_target()
def get_target_state(self):
"""
Get the density matrix representation of the target state
"""
state = partial_trace(self.target_state, 2, 4, 2)
return state.numpy()
def get_generated_state(self):
"""
Get the density matrix representation of the generated state
"""
state = self.generator()
state = partial_trace(state, 2, 4, 2)
return state.numpy()
def train(self):
"""
Train the QGAN
"""
# Used to record the change of loss value
loss_history = []
pbar = tqdm(
desc="Training: ",
total=self.ITR * (self.ITR_G + self.ITR_D),
ncols=100,
ascii=True,
)
for _ in range(self.ITR):
# Train the discriminator
loss_disc_history = []
for _ in range(self.ITR_D):
pbar.update(1)
loss_disc = self.disc_loss_func()
loss_disc.backward()
self.optimizer.minimize(
loss_disc,
parameters=self.discriminator.parameters(),
no_grad_set=self.generator.parameters(),
)
self.optimizer.clear_grad()
loss_disc_history.append(loss_disc.numpy()[0])
# Train the generator
loss_gen_history = []
for _ in range(self.ITR_G):
pbar.update(1)
loss_gen = self.gen_loss_func()
loss_gen.backward()
self.optimizer.minimize(
loss_gen,
parameters=self.generator.parameters(),
no_grad_set=self.discriminator.parameters(),
)
self.optimizer.clear_grad()
loss_gen_history.append(loss_gen.numpy()[0])
loss_history.append((loss_disc_history, loss_gen_history))
pbar.close()
return loss_history
Next, we use PaddlePaddle to train our model.
# Learning rate
LR = 0.1
# Total number of iterations
ITR = 25
# In each iteration, the number of iterations of the discriminator
ITR1 = 40
# In each iteration, the number of generator iterations
ITR2 = 50
# prepare the target quantum state
target_state = zero_state(num_qubits=3)
target_state = RY(0, param=0.9 * np.pi)(target_state)
target_state = RZ(0, param=0.2 * np.pi)(target_state)
paddle.seed(18)
# Construct a QGAN and train
gan_demo = QGAN(target_state, LR, ITR, ITR1, ITR2)
loss_history = gan_demo.train()
# Get the target quantum state
target_state = gan_demo.get_target_state()
# Get the final quantum state generated by the generator
gen_state = gan_demo.get_generated_state()
print("the density matrix of the target state:")
print(target_state, "\n")
print("the density matrix of the generated state:")
print(gen_state, "\n")
# Calculate the distance between two quantum states,
# The distance here is defined as tr[(target_state-gen_state)^2]
distance = np.trace(np.matmul(target_state-gen_state, target_state-gen_state)).real
# Calculate the fidelity of two quantum states
fidelity = np.trace(
scipy.linalg.sqrtm(scipy.linalg.sqrtm(target_state) @ gen_state @ scipy.linalg.sqrtm(gen_state))
).real
print("the distance between these two quantum states is", distance, "\n")
print("the fidelity between these two quantum states is", fidelity)
Training: 100%|#################################################| 2250/2250 [00:51<00:00, 43.51it/s]
the density matrix of the target state: [[0.02447175+0.j 0.12500004-0.09081785j] [0.12500004+0.09081785j 0.97552836+0.j ]] the density matrix of the generated state: [[0.02444273-1.0244548e-08j 0.12302139-9.3332976e-02j] [0.12302142+9.3332976e-02j 0.9755573 +0.0000000e+00j]] the distance between these two quantum states is 2.0483465e-05 the fidelity between these two quantum states is 0.9999945609564611
We compare the target quantum state's density matrix $\rho_\text{target}$ and the generated quantum state's density matrix $\rho_\text{gen}$ and calculate the distance between them $\text{tr}[(\rho_\text{target}-\rho_\text{gen})^2]$ and fidelity. We can know that our generator generates a quantum state very close to the target state.
Visualization of the training process¶
Next, let's observe the change of the discriminator and generator's loss curve during the training process.
First install the required packages.
from IPython.display import clear_output
%pip install celluloid
clear_output()
Next, we draw the change of the loss curve.
import matplotlib.pyplot as plt
from celluloid import Camera
def draw_pic(loss_history):
fig, axes = plt.subplots(nrows=1, ncols=2)
camera = Camera(fig)
axes[0].set_title("discriminator")
axes[0].set_xlabel("disc_iter")
axes[0].set_ylabel("disc_loss")
axes[0].set_xlim(0, 20)
axes[0].set_ylim(-1, 1)
axes[1].set_title("generator")
axes[1].set_xlabel("gen_iter")
axes[1].set_ylabel("gen_loss")
axes[1].set_xlim(0, 50)
axes[1].set_ylim(-1, 0)
for loss in loss_history:
disc_data, gen_data = loss
disc_x_data = range(len(disc_data))
gen_x_data = range(len(gen_data))
axes[0].plot(disc_x_data, disc_data, color='red')
axes[1].plot(gen_x_data, gen_data, color='blue')
camera.snap()
animation = camera.animate(interval=600,
repeat=True, repeat_delay=800)
animation.save("./figures/QGAN-fig-loss.gif")
draw_pic(loss_history)
clear_output()

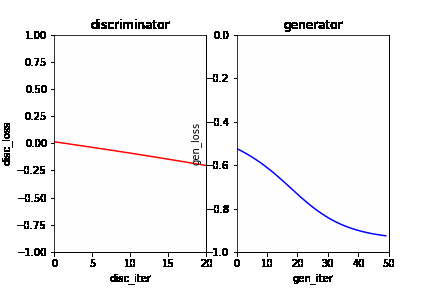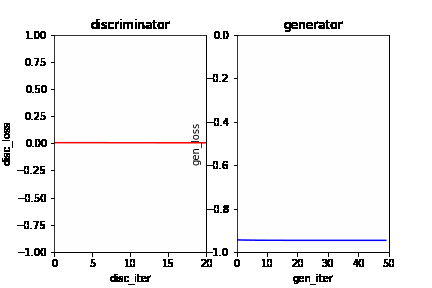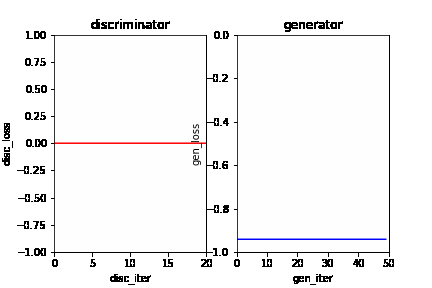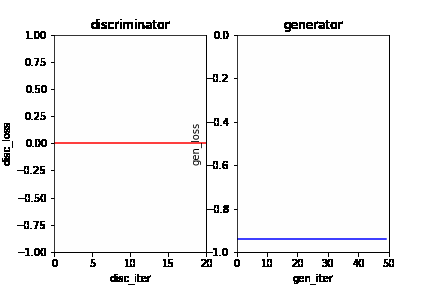
In this dynamic picture, each frame represents an iterative process. In an iteration, the red line on the left represents the loss curve of the discriminator, and the blue line on the right represents the loss curve of the generator. It can be seen that at the initial stage, the discriminator and generator can gradually learn from a poor discriminant ability and generation ability to a better discrimination ability and generation ability in the current situation. As the learning progresses, the generator’s generation ability is getting stronger and stronger, and the discriminator’s ability is getting stronger and stronger. However, the discriminator can not distinguish the real data and the generated data because the generator has generated data close to real data. At this time, the model has converged.
References¶
[1] Goodfellow, I. J. et al. Generative Adversarial Nets. Proc. 27th Int. Conf. Neural Inf. Process. Syst. (2014).
[2] Lloyd, S. & Weedbrook, C. Quantum Generative Adversarial Learning. Phys. Rev. Lett. 121, 040502 (2018).
[3] Benedetti, M., Grant, E., Wossnig, L. & Severini, S. Adversarial quantum circuit learning for pure state approximation. New J. Phys. 21, (2019).